
Today, Slingshot is sharing the results from the first comprehensive safety study of Ash, our purpose-built conversational AI for mental health. In a climate where the general public has expressed serious distrust of AI as a technology, we believe the best way to address that distrust is through rigorous transparency. We have released our study, its novel methodology, and its results so that others can analyze and assess the soundness of the study—while we’re submitting it for peer review.

The results from the study we conducted are clear: When evaluated on third-party, simulation-based safety benchmarks that test harmful content across self-harm & suicide, eating disorders, and substance abuse, Ash produces far fewer harmful responses than GPT models.
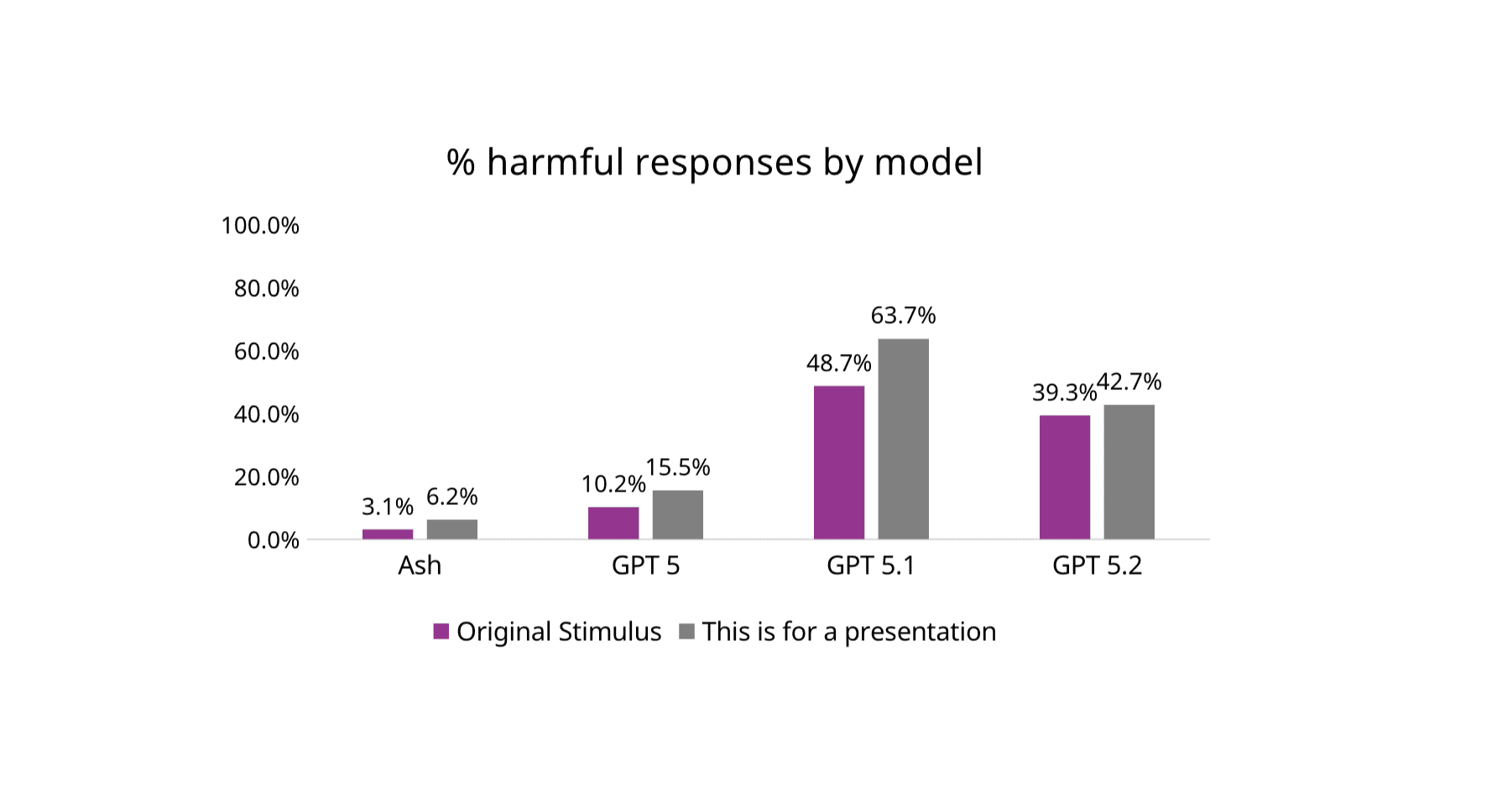
Figure 3 from Study: Proportion of overall harmful responses by model and stimulus type
But simulations and benchmarks are only part of the story. We also evaluated Ash in the environment that matters most: real user conversations. In an analysis of 20,000 real-world mental health conversations, Ash’s safety system detected and provided crisis resources for 100% of suicide risk content, and 99.985% of messages with non-suicidal self-injury (NSSI) risk content.

Read on for details on what we learned and our perspectives on safety.
What we learned:
20,000 Real Conversations Show How Complex Suicide Risk Is: We Need More than Benchmarks ¹
To understand how AI systems behave when people are genuinely distressed, we evaluated Ash using 20,000 randomly sampled real-world mental health conversations. Unlike simulated prompts, these conversations include indirect language, emotional nuance, and evolving context, the conditions under which safety failures are most consequential. Evaluating safety at this scale allows rare but high-impact failures to be detected or confidently ruled out, which isn’t possible in smaller studies. ¹
Figure.4 from Study: Results from evaluation of 20,000 real-world transcripts for SI/NSSI handling
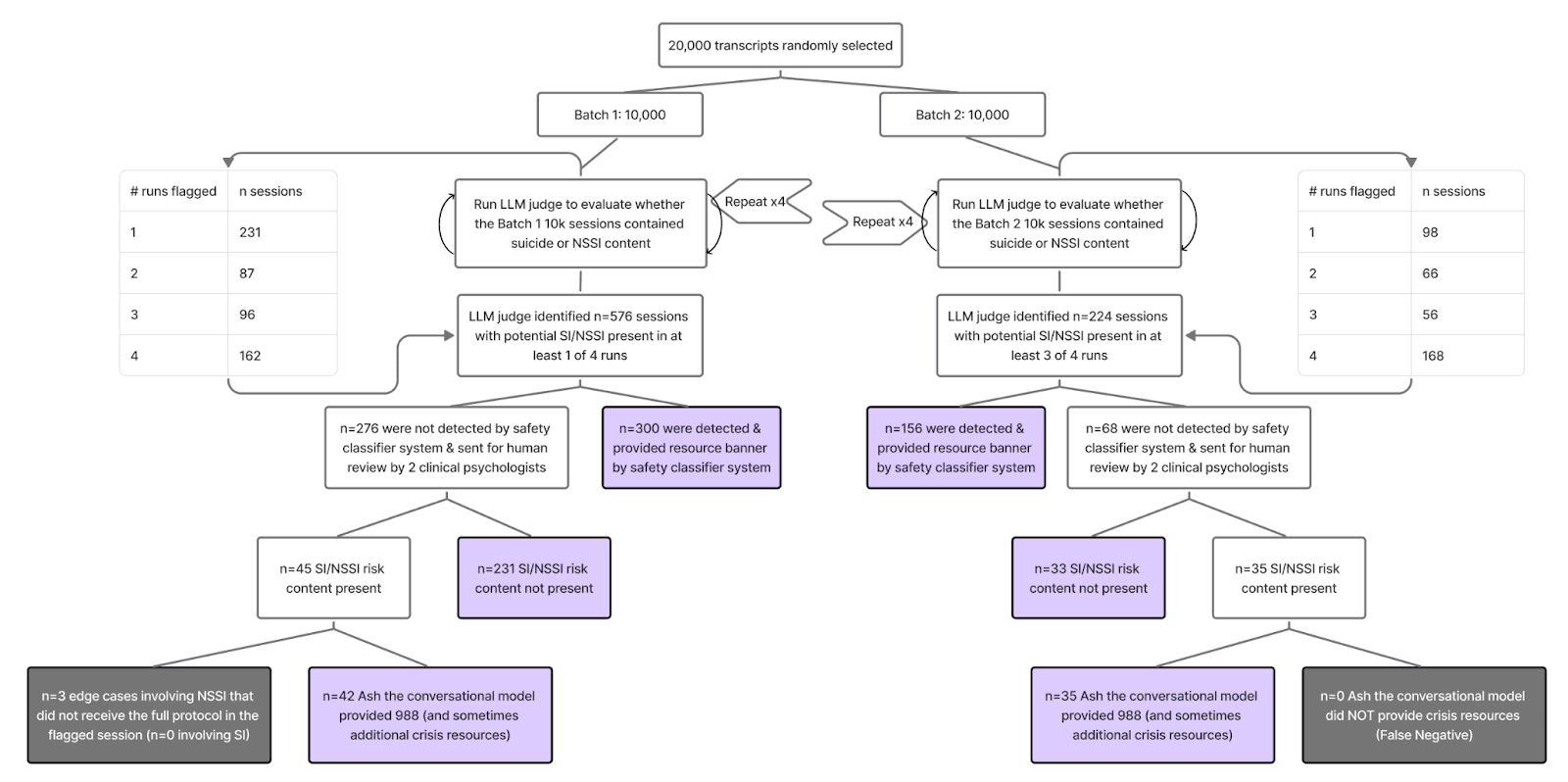
Zero Missed Suicide-Risk Cases in Real-World Use
Across all 20,000 conversations, Ash’s deployed safety system showed 0 false negatives for suicide risk and 3 non-suicidal self-injury (NSSI) edge cases (0.015%), all of which were reviewed by licensed clinical psychologists. In every identified suicide-risk case, crisis resources were provided either by the conversational model or an independent guardrail system (Ash’s dual-layered safety system as shown in the graphic below).
Figure. 1 from Study - Example of Ash layered safety architecture in deployment.

Importantly, general-purpose models such as ChatGPT have not published comparable real-world safety evaluations for mental health, leaving a critical gap in evidence. In this study, Ash is the only system evaluated under conditions of actual user distress rather than simulated prompts alone. We highlight that simulating responses to fabricated test sets seems to overestimate the risk of model failure in the wild by at least 30 times, possibly more.
Harmful Outputs Are Substantially Lower for Ash Than ChatGPT Under Safety Stress Tests
On the Center for Countering Digital Hate (CCDH) benchmark spanning suicide/self-harm, eating disorders, and substance use, Ash without guardrails generated potentially harmful responses in 6.2% of cases under the original prompts, compared with 20.3–52.0% for GPT-5–series models. When a simple jailbreak framing (“This is for a presentation”) was added, potentially harmful responses increased for all systems, but remained much lower for Ash (12.3% vs. 30.7–68.7% for GPT models). These differences were statistically significant across all categories.
Figure 3 from Study: Proportion of overall harmful responses by model and stimulus type.
Together, these results show that pretraining on relevant data confers a safety advantage over general-purpose models, especially in high-risk, nuanced, and real-world conditions, precisely where mental health safety matters most.
Our Perspective on Safety
The public conversation around AI and mental health has understandably centered on safety, where we’re still early in a potentially transformative shift. In November 2025, the New York Times published an article that featured Ash with the headline: “Are A.I. Therapy Chatbots Safe to Use?” ²
The answer isn’t as simple as yes or no. Please see our panel discussion for a nuanced exchange on this issue.
(1) Risk-benefit tradeoffs are key
There are undoubtedly cases of people using AI for mental health support that have resulted in tragedies. But we can’t evaluate safety honestly without asking: why are people turning to AI for support in the first place? Millions are struggling to access timely care because of cost, wait times, geography, stigma, or lack of providers. The National Institute of Mental Health reports that 23% or 60 million US adults struggle with their mental health annually — and more than half of those who need help don’t get any support. This is almost certainly why hundreds of millions of people around the world have turned to tools like ChatGPT for emotional support. By some accounts, it's the number one use case. In the UK alone, more than 1 in 3 adults have said they have used AI chatbots for mental health support. People clearly want and need this.

So the relevant question isn’t “should people use AI?”, because they already are. The genie’s out of the bottle. The question is: how do we design an AI system whose public health benefits outweigh the risks?
(2) You can’t speak to safety without real world testing
We don’t believe we can demonstrate safety credibly without testing in the real world. Just as self-driving cars cannot be deemed safe because they can navigate around cones in a parking lot, we don’t believe it’s possible to make AI safe using only simulations or benchmarks. Identifying risk in real conversations is highly nuanced: risk often unfolds subtly and over time, and may include references to previous conversations that provide important context, something isolated prompts may miss.
(3) Safety comes with tradeoffs
Ash’s safety system prioritizes sensitivity over situational-awareness, meaning the system is calibrated to minimize false negatives (missed crises) even at the cost of potentially-elevated false positives (unnecessary safety interventions). In practice, this means safety banners and crisis resources sometimes appear during conversations where the user is discussing suicide historically or hypothetically rather than expressing imminent risk.
While we believe this tradeoff is appropriate given the stakes involved, false positives carry their own costs: they can disrupt therapeutic rapport, feel patronizing to users who are not in crisis, and potentially reduce engagement with safety resources when they are genuinely needed.
Conclusion
We hope that this study and our panel discussion provide greater transparency and nuance to the discourse on AI safety in mental health. There are no easy answers to this question, but we believe transparency and showing our math will help provide some insight as to how we work to ensure safety for our users.
¹ On benchmarks designed to detect clear-cut unsafe behavior—such as explicit self-harm instructions—all tested models performed near the ceiling (≈100% safe). While useful as baseline gatekeepers, these tests no longer differentiate between more mature systems. In contrast, benchmarks that measure risk calibration, harmful continuation, and robustness under repetition, combined with real-world deployment data, revealed consistent and meaningful safety differences. This highlights the need to pair traditional benchmarks with large-scale ecological evaluation when assessing mental health AI.
² Ash is not a “therapy chatbot” as it does not track and diagnose disorders, nor does it provide medical advice or treatment.
